P
Loading blog...
Loading blog...
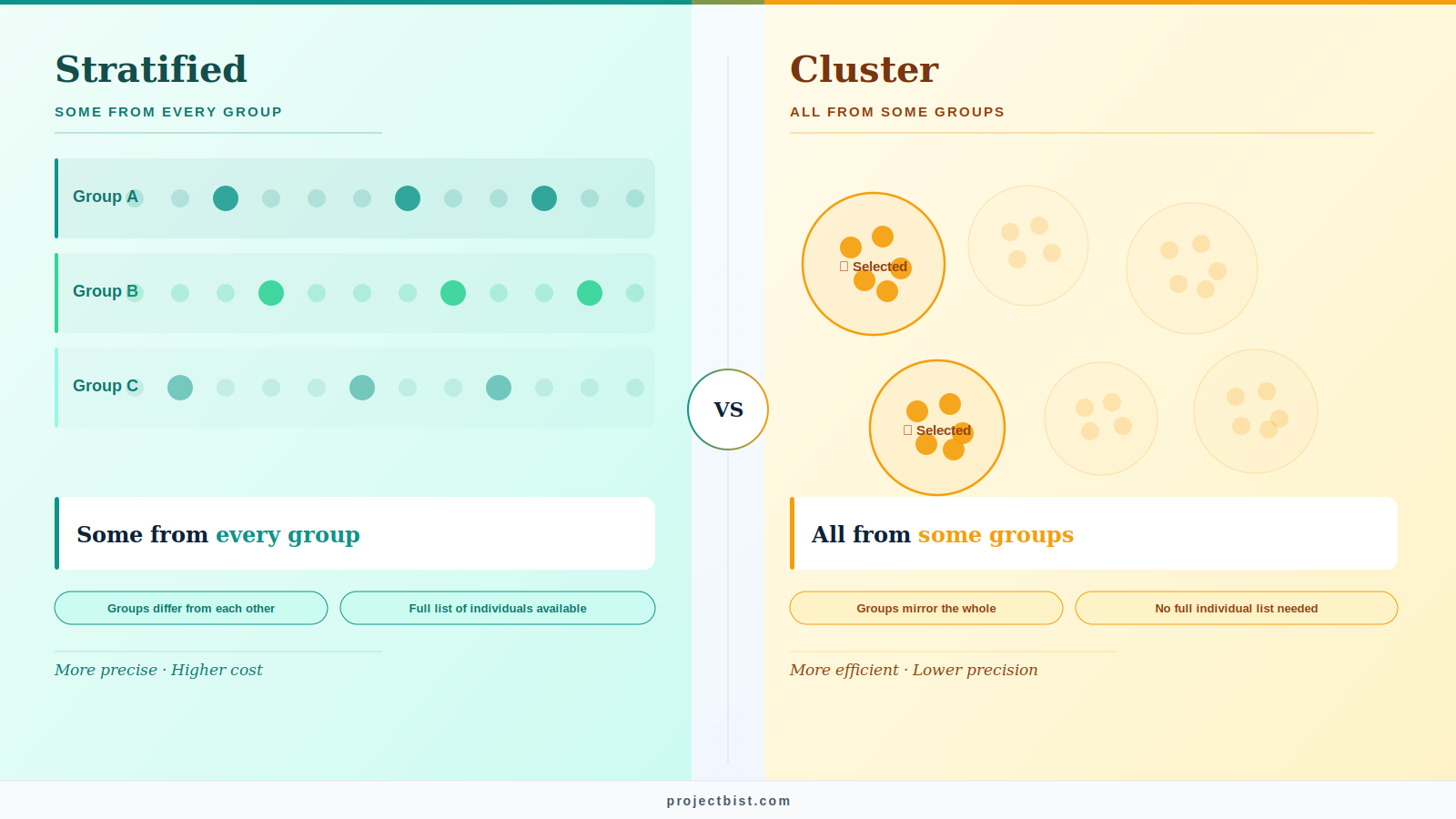
Both methods divide a population into groups. Everything else about them is different.
Ravi Menon
Mar 31, 2026•5 min read
Both methods divide a population into groups before selecting a sample. That is where the similarity ends.
Researchers who confuse stratified and cluster sampling often design studies that are either more expensive than they need to be or less representative than the question requires. The choice between them is not just methodological. It has real consequences for cost, precision, and the reliability of your findings.
You divide the population into distinct subgroups called strata, based on a characteristic that matters for your research question. Age, gender, income level, geographic region. Then you randomly select individuals from each stratum.
The key feature: you sample from every stratum. No stratum is left out. This gives you a sample that proportionally represents the full diversity of the population.
You divide the population into naturally occurring groups called clusters, typically by geography. Schools, neighborhoods, local government areas, villages. Then you randomly select some clusters and include everyone in those selected clusters.
The key feature: you sample entire groups, not individuals from all groups. Selected clusters are fully sampled. Unselected clusters are ignored entirely.
Stratified sampling says: include some people from every group. Cluster sampling says: include all people from some groups.
There is a straightforward way to choose between them:
The fastest way to decide is to look carefully at the relationship between your groups and your population.
Ask yourself this question: are the groups in my population similar to each other on the inside, or different from each other?
If the groups are internally different from each other — meaning the people within each group share a key characteristic that makes them distinct from other groups — use stratified sampling. You want representation from every group because the differences between groups matter to your findings.
If the groups are internally similar to each other — meaning any one group could reasonably stand in for the whole population — use cluster sampling. You can afford to sample only some groups because each group already reflects the diversity of the whole.
A second question helps confirm: do you have a complete list of individuals in the population, or do you only know the groups?
If you have a full list, stratified sampling is feasible. If you only know the natural groupings (the schools in a district, the villages in a region, the branches of a bank), cluster sampling is more practical because you sample entire groups rather than hunting for individuals across all of them.
Consumer research where you need equal representation across age or income groups. Health surveys where gender or location significantly affects outcomes. Policy studies where you need to compare specific subpopulations. Any study where the subgroups are known in advance and each one needs to appear in the findings.
Example: A study measuring vaccination rates among children under five in a country. The population naturally splits by wealth quintile — the poorest households are significantly different from the wealthiest in their access to health services. Each wealth group behaves differently in ways that matter directly to the research question. Stratified sampling is correct here. You need representation from every income level.
National household surveys where traveling to every location is prohibitively expensive. School-based research where entire classrooms or schools are the natural sampling unit. Agricultural or rural field studies where communities are the logical unit of analysis. Multi-stage surveys where you first select regions and then sample within them.
Example: A study evaluating teacher performance across 800 primary schools in a region. You cannot visit all 800 schools. But any randomly selected group of schools, taken as a whole, will reflect the range of school sizes, urban and rural settings, and resource levels that exist across the region. Cluster sampling is correct here. You randomly select 60 schools and assess all teachers in those schools.
Stratified sampling is more precise. It reduces sampling error by ensuring all key groups are represented. The downside is cost: you may need to sample in many locations or from many subgroups, which adds time and fieldwork expense.
Cluster sampling is more efficient. You concentrate data collection in fewer locations, which reduces travel and logistics costs significantly. The downside is reduced precision: within-cluster similarity can inflate sampling error if clusters are not genuinely representative of the whole population.
Yes, and in large-scale surveys this is common. You first stratify the population by region or urban/rural classification. Then within each stratum, you select clusters randomly. This is called stratified cluster sampling or multi-stage sampling. It balances representativeness with operational efficiency, which is why it is the standard design for national demographic and health surveys, LSMS studies, and many large development research programs.
The right sampling method is the one that fits both your research question and your operational constraints. Understanding the difference between these two methods is not academic. It directly affects whether your findings can be trusted.
ProjectBist connects you with verified research professionals across all disciplines.
Search Research Professionalsarrow_forwardSources: Wikipedia Cluster Sampling; Statology; Greenbook GRIT; Dovetail Research; Key Differences; GeeksforGeeks Statistics
Newsletter
Personalize your updates! Subscribe to ProjectBist's Newsletter and choose from the following categories.
Ethnographic Research: How to Study Culture and Community by Being Present in Ways Other Methods Cannot
Survey Translation and Back-Translation: How to Ensure Your Instrument Means the Same Thing in Every Language

How to Build a Research Firm From Scratch: What the First Three Years Actually Require