P
Loading blog...
Loading blog...
When you need to test more than one product concept with the same respondents, how you sequence the evaluation determines whether your data is reliable or not.
Priya Nair
Apr 09, 2026•5 min read
You have three new packaging designs ready for testing. You want to know which one performs best. You also want to know how each one performs individually, not just relative to the others. And you need a sample size you can actually afford.
This is exactly the problem sequential monadic testing was built to solve.
To understand sequential monadic testing, it helps to know the alternatives:
Each respondent sees only one product or concept. Three products means three separate respondent groups. Every evaluation is completely independent and uninfluenced by any other product. This is the gold standard for validity because it most closely mirrors real-world conditions where a consumer encounters one product at a time. The downside: it requires the largest sample size, since each group needs to be large enough to produce statistically reliable estimates independently.
Respondents are shown two products simultaneously and asked which they prefer. This is highly sensitive to small differences but sacrifices validity: the head-to-head comparison exaggerates differences, and the result tells you which product is preferred relative to the other, not how each product stands on its own merits.
Each respondent evaluates multiple products, one at a time, in sequence. They see Product A and rate it independently. Then they see Product B and rate it independently. Then, after evaluating each product on its own, they are asked to make a direct comparison.
This design gives you the best of both worlds: individual product scores that are captured before comparison bias has set in, plus comparative preference data from the same respondents. It is more cost-efficient than pure monadic testing because each respondent contributes data on multiple products.
Sequential monadic testing is not just about efficiency. It is about capturing both the independent evaluation and the comparative judgment from the same person — because both types of data answer different questions.
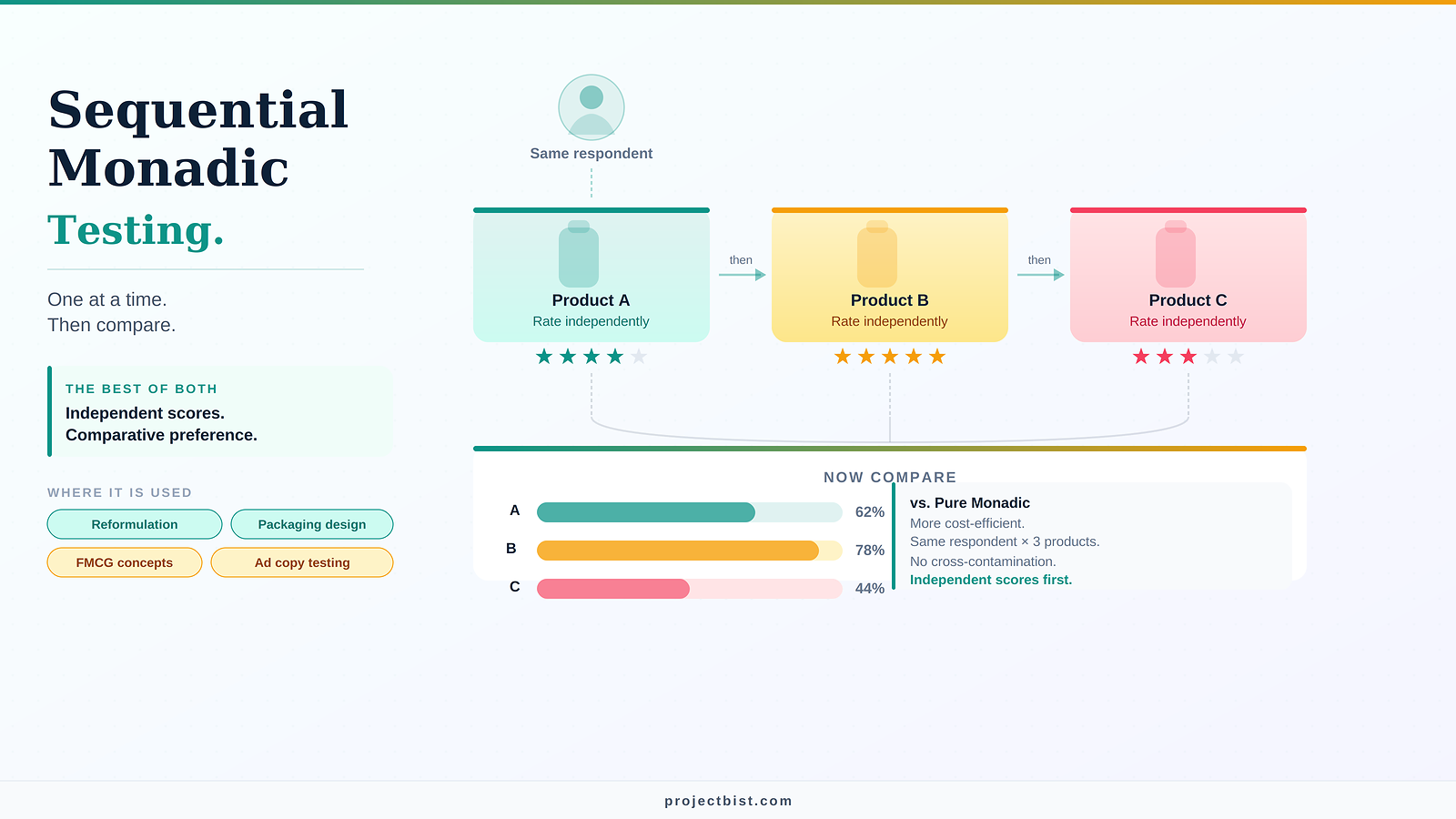
There is a well-documented phenomenon in sequential monadic research called the suppression effect. When respondents evaluate multiple products in sequence, all scores are systematically lower than they would be in a pure monadic study. Respondents become more critical after evaluating the first product, because the first product becomes an unconscious reference point for every subsequent evaluation.
The practical implication: you cannot directly compare scores from a sequential monadic study with scores from a pure monadic study using the same scale. They are not on the same baseline. If you have historical norms from monadic studies, build a conversion factor into your analysis, or run a pure monadic control group alongside the sequential monadic study.
The sequence in which products are presented also affects scores. The first product evaluated often receives higher scores because it has no competition yet. The last product can suffer from fatigue or contrast effects. These order biases are managed by randomizing the presentation sequence across respondents.
In a study testing three products with 300 respondents, each product should appear in each position (first, second, third) for approximately 100 respondents. This rotation ensures that order effects are distributed evenly and do not systematically inflate or deflate any single product's scores.
According to Ipsos's product testing guidance, pure monadic testing is preferred when product differences are clear and substantial. If you are testing a dramatically reformulated product against the existing version, pure monadic gives you cleaner, more externally valid results. Sequential monadic is better suited to subtle differences, where the sensitivity of having the same respondent evaluate both products helps detect small distinctions that separate groups might miss.
A common refinement of sequential monadic testing is the proto-monadic design. Respondents evaluate the first product monadically (in complete isolation), then evaluate a second product, and then are asked to make a direct paired comparison between the two. This structure preserves the pure monadic validity of the first product's evaluation while also providing comparative data. Many FMCG and CPG researchers prefer this design for concept and formula testing because it combines the rigour of monadic evaluation with the efficiency and comparative insight of sequential testing.
What is the main difference between sequential monadic and pure monadic testing?
In pure monadic testing, each respondent evaluates only one product. In sequential monadic testing, each respondent evaluates multiple products in sequence. Pure monadic produces more externally valid scores but requires a larger sample. Sequential monadic is more cost-efficient and provides comparative data but introduces the suppression effect, where all scores are slightly lower than they would be in a pure monadic study.
How many products can be tested in a single sequential monadic study?
Two to three products is the practical range for most studies. Beyond three, respondent fatigue significantly affects the reliability of later evaluations. For four or more products, split the study into multiple sequential monadic sessions or use a different design.
Does sequential monadic testing work for sensory research?
It depends on the product category. For visual stimuli like packaging or advertising, sequential monadic works well because there is no sensory fatigue. For taste or smell-based evaluations, you need to manage palate fatigue between products, which limits how many products can be evaluated in a single session.
Can I compare sequential monadic scores to historical norms from pure monadic studies?
Not directly. The suppression effect means sequential monadic scores are systematically lower. If you need normative comparison, include a monadic control group in the same study, or apply a statistical correction factor based on past studies where both designs were run simultaneously.
Sources: Drive Research — Monadic vs Sequential Monadic Testing (2026); Ipsos — Product Testing: Handle with Care; Decision Analyst — Product Testing White Paper; Let's Highlight — The Advantage of Monadic Concept Testing; SurveyNinja Glossary — Sequential Monadic Testing
Newsletter
Personalize your updates! Subscribe to ProjectBist's Newsletter and choose from the following categories.
Ethnographic Research: How to Study Culture and Community by Being Present in Ways Other Methods Cannot
Survey Translation and Back-Translation: How to Ensure Your Instrument Means the Same Thing in Every Language

How to Build a Research Firm From Scratch: What the First Three Years Actually Require